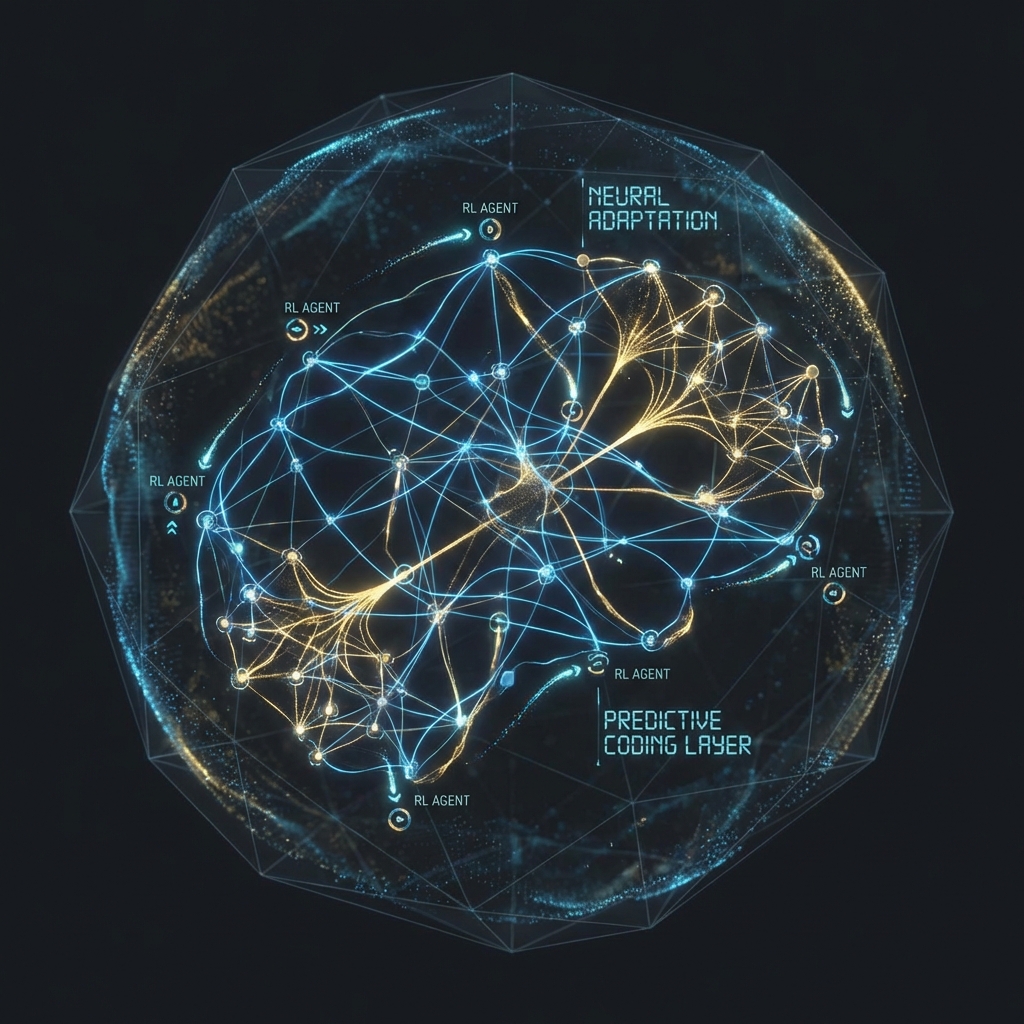
Synaptic Architect - MARL for Neural Structure Learning
A novel approach where neurons act as RL agents, learning to modify network structure through Multi-Agent Reinforcement Learning on Predictive Coding networks.
Synaptic Architect: MARL for Predictive Coding Networks
Research Overview
What if neural networks could learn their own optimal structure? This project explores that question by treating individual neurons as reinforcement learning agents that learn to modify the network they inhabit.
The core insight: combine Predictive Coding (a biologically-plausible learning framework) with Multi-Agent Reinforcement Learning to enable emergent structural adaptation.
The Big Idea
Traditional neural networks have fixed architectures designed by humans. We specify the number of layers, neurons per layer, and connection patterns. But biological brains don’t work this way—they continuously rewire based on experience.
Synaptic Architect flips the script:
- Neurons as Agents: Each hidden neuron is an RL agent
- Structure as Action: Agents can add or prune connections
- PC as Environment: The Predictive Coding dynamics provide the learning signal
- Emergent Hierarchy: Optimal structure emerges from agent interactions
Technical Architecture
Two Timescales
Fast Timescale (Predictive Coding):
- Forward pass computes layer activations
- Errors propagate backward (PC-style)
- Local Hebbian learning updates weights
- Homeostatic adaptation of thresholds
Slow Timescale (MARL):
- Agents observe local network state
- Select structural actions (add/prune/no-op)
- Network runs PC epochs
- Rewards based on prediction error reduction
PC-PPO Algorithm
A novel contribution: the PPO agents’ actor and critic networks are themselves Predictive Coding architectures:
┌─────────────────────────────────────────────────────────────┐
│ MARL Layer (Slow) │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ │
│ │ Agent 1 │ │ Agent 2 │ │ Agent N │ ... │
│ │ (PPO) │ │ (PPO) │ │ (PPO) │ │
│ └────┬─────┘ └────┬─────┘ └────┬─────┘ │
│ │ │ │ │
│ ▼ ▼ ▼ │
│ ┌─────────────────────────────────────────────────────┐ │
│ │ Shared PCN Actor/Critic │ │
│ └─────────────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────────────┘
│
▼ (structural actions)
┌─────────────────────────────────────────────────────────────┐
│ PC Layer (Fast) │
│ ┌─────────┐ ┌─────────┐ ┌─────────┐ │
│ │ Neuron 1│◀──▶│ Neuron 2│◀──▶│ Neuron 3│ ... │
│ └─────────┘ └─────────┘ └─────────┘ │
│ │ │ │ │
│ └───────────────┴───────────────┘ │
│ Vectorized PC Operations │
└─────────────────────────────────────────────────────────────┘
Agent State & Reward
Local State (per neuron):
- Current activation
- Prediction error
- Total confusion (error volatility)
- Threshold value
- Connection statistics
Reward Signal:
R_total = α * R_global + (1-α) * R_local - action_cost
R_global = Δ(task_accuracy)
R_local = -|prediction_error| - β * |total_confusion|
Implementation Details
Vectorized PC Operations
For performance, PC computations use vectorized tensor operations:
# Forward pass (vectorized)
for layer_idx in range(1, num_layers):
pre = self.layer_activations[layer_idx - 1]
linear = self.linear_layers[layer_idx - 1]
raw = linear(pre)
self.layer_activations[layer_idx] = torch.sigmoid(raw)
# Weight update (vectorized Hebbian)
delta_W = lr * E_post.T @ A_pre
linear.weight.data += delta_W
PPO with Centralized Critic
- Shared Actor: All agents use same policy network
- Centralized Critic: Takes global network state
- GAE: Generalized Advantage Estimation for stable updates
# Collect rollout
for step in range(steps_per_agent):
local_states = network.get_rl_agent_states()
global_state = network.get_global_state_for_critic()
actions, log_probs = actor.select_actions(local_states)
values = critic(global_state)
network.apply_rl_actions(actions)
network.run_pc_epoch()
rewards = calculate_rewards(network, actions)
buffer.store(local_states, global_state, actions,
log_probs, rewards, values)
Project Structure
PCPPO/
├── pc_core/
│ ├── neuron.py # Neuron metadata classes
│ └── network.py # Vectorized PC network
├── pcppo_marl/
│ ├── pcn_models.py # PC-based Actor/Critic
│ ├── ppo_core.py # PPO loss functions
│ ├── experience_buffer.py
│ ├── agent_manager.py
│ └── marl_trainer.py # Main training loop
├── tasks/
│ └── mnist_loader.py # MNIST for evaluation
├── utils/
│ ├── config_parser.py
│ ├── logger.py # TensorBoard + W&B
│ └── visualization.py
├── main.py
└── config.yaml
Current Status & Roadmap
Implemented ✅
- Vectorized PC network with
nn.Linearlayers - MARL training loop with PPO
- Shared actor, centralized critic
- Experience buffer with GAE
- Comprehensive logging (TensorBoard, W&B)
In Progress 🔄
- Tier 1: Actual structural plasticity (add/prune via weight masks)
- Tier 2: Module-level agents (reduce variance)
- Tier 2: Counterfactual reward calculation
Future Work 📋
- Connectivity-aware agent observations
- Curriculum scheduling for PC epochs
- Multi-task evaluation
What I Learned
- Predictive Coding Theory: Deep dive into free energy principle and hierarchical processing
- MARL Challenges: Credit assignment in multi-agent systems
- Vectorization: Balancing individual agent semantics with batch efficiency
- Research Engineering: Managing complex experimental configurations
- Novel Algorithm Design: Combining ideas from different fields
Key Insight
Traditional ML uses global optimization. This PC-MARL approach shows that intelligent structure might emerge from purely local learning rules, where each neuron simply tries to minimize its prediction error while occasionally restructuring its connections.
This is more biologically plausible and potentially more robust to distribution shift.
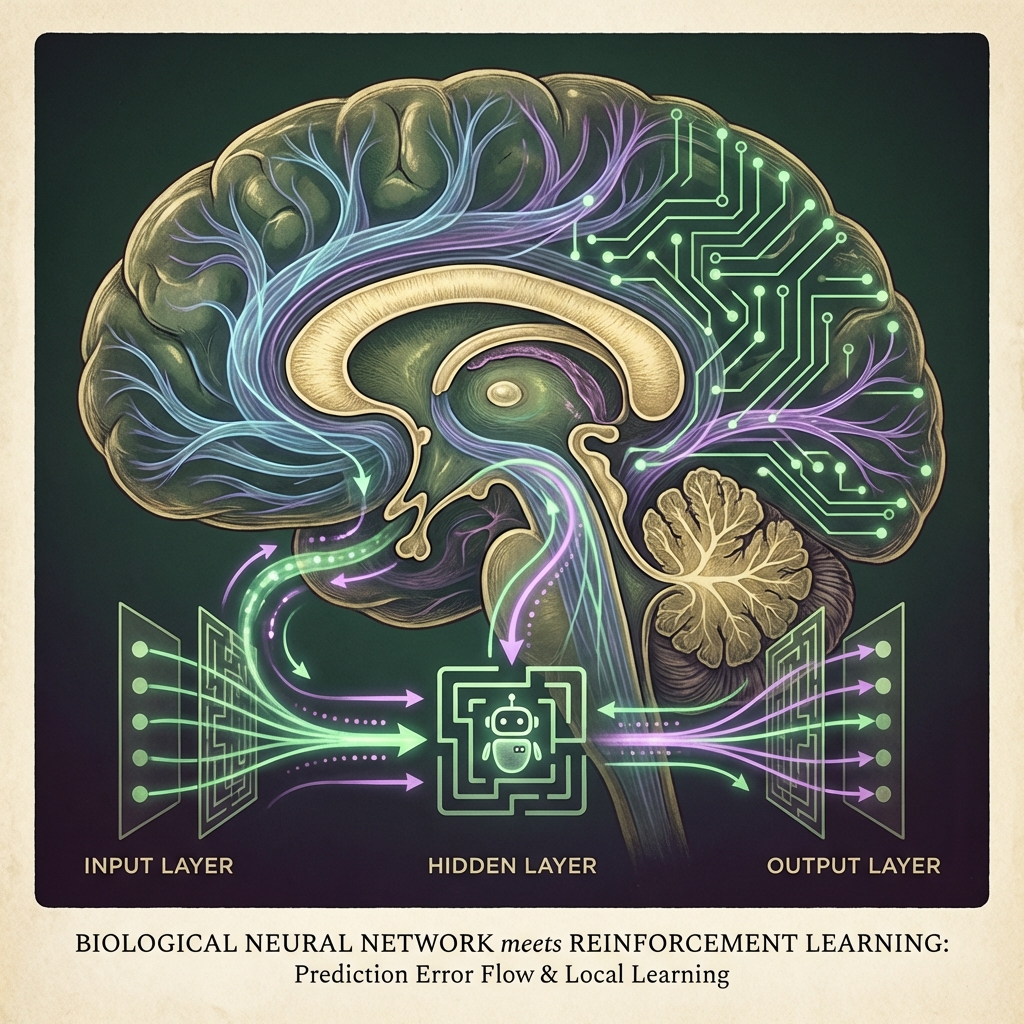
PC-RL - Biologically-Plausible Reinforcement Learning
{kind=link}
You Might Also Like

Video-to-Motion Capture Pipeline
QuickEasyTools - Privacy-First Online Utilities
